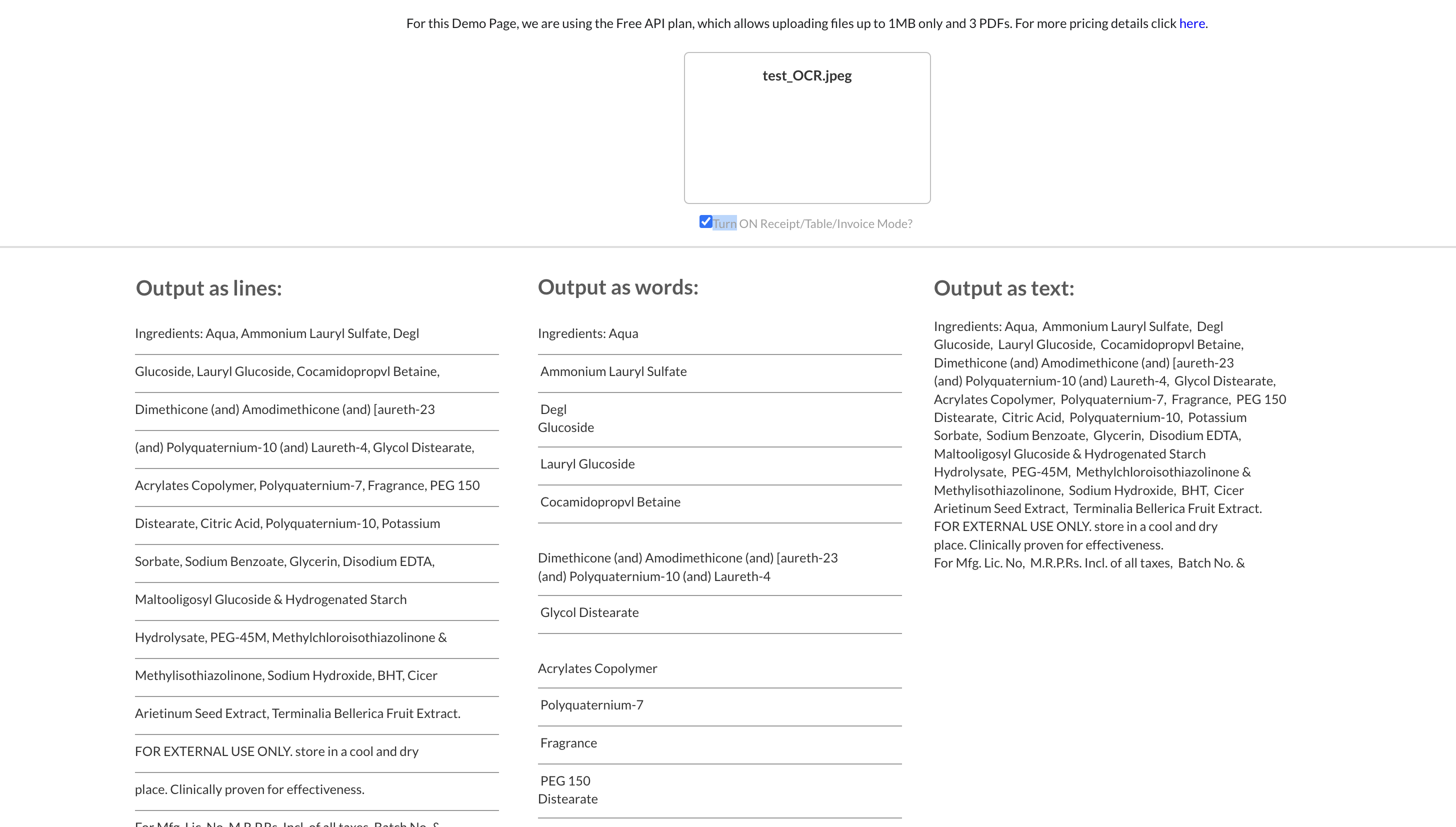
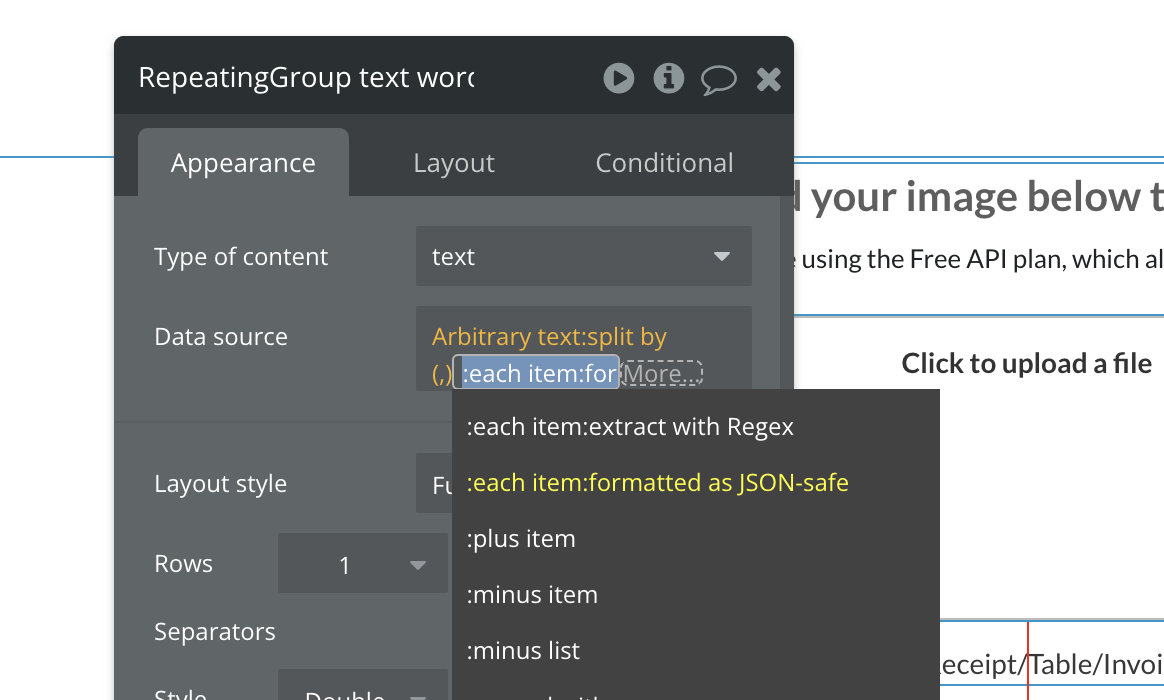
I’ve been using the OCR service for a month or more now with great results mostly. I’m using the service to extract text from images and then match that text to items in my DB. For the most part it works very well and I’ve been able to come up with work arounds for the few minor issues I had except for one thing. when text goes to a new line in the middle of a value the extracted text also does this and I can’t get bubble to recognize the item since it’s no longer an exact match. An example
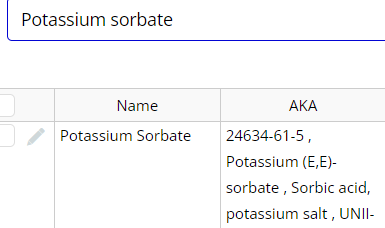
item in data is -
“On One Line”
extracted text reads as -
This would normally work if it was on
one line, but since it split in the middle of the value I want to match, it doesn’t work.
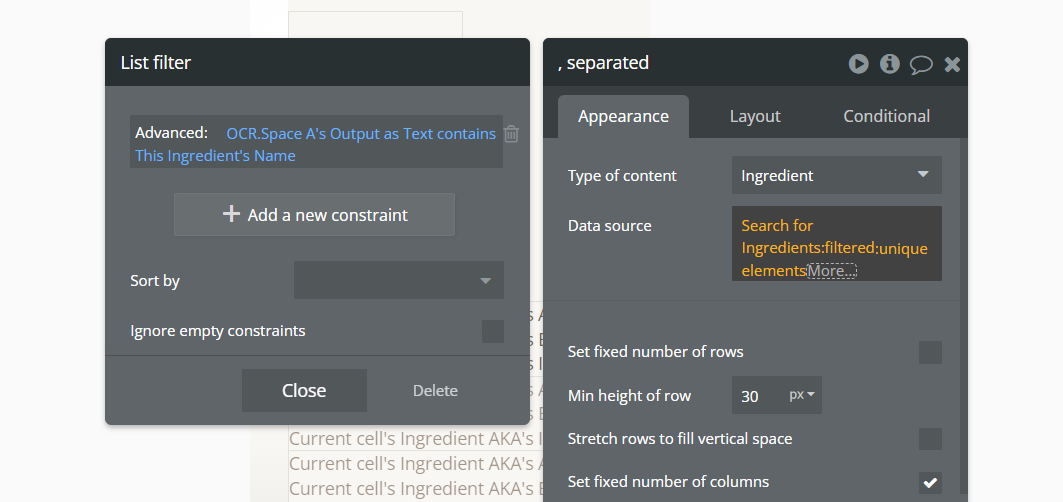
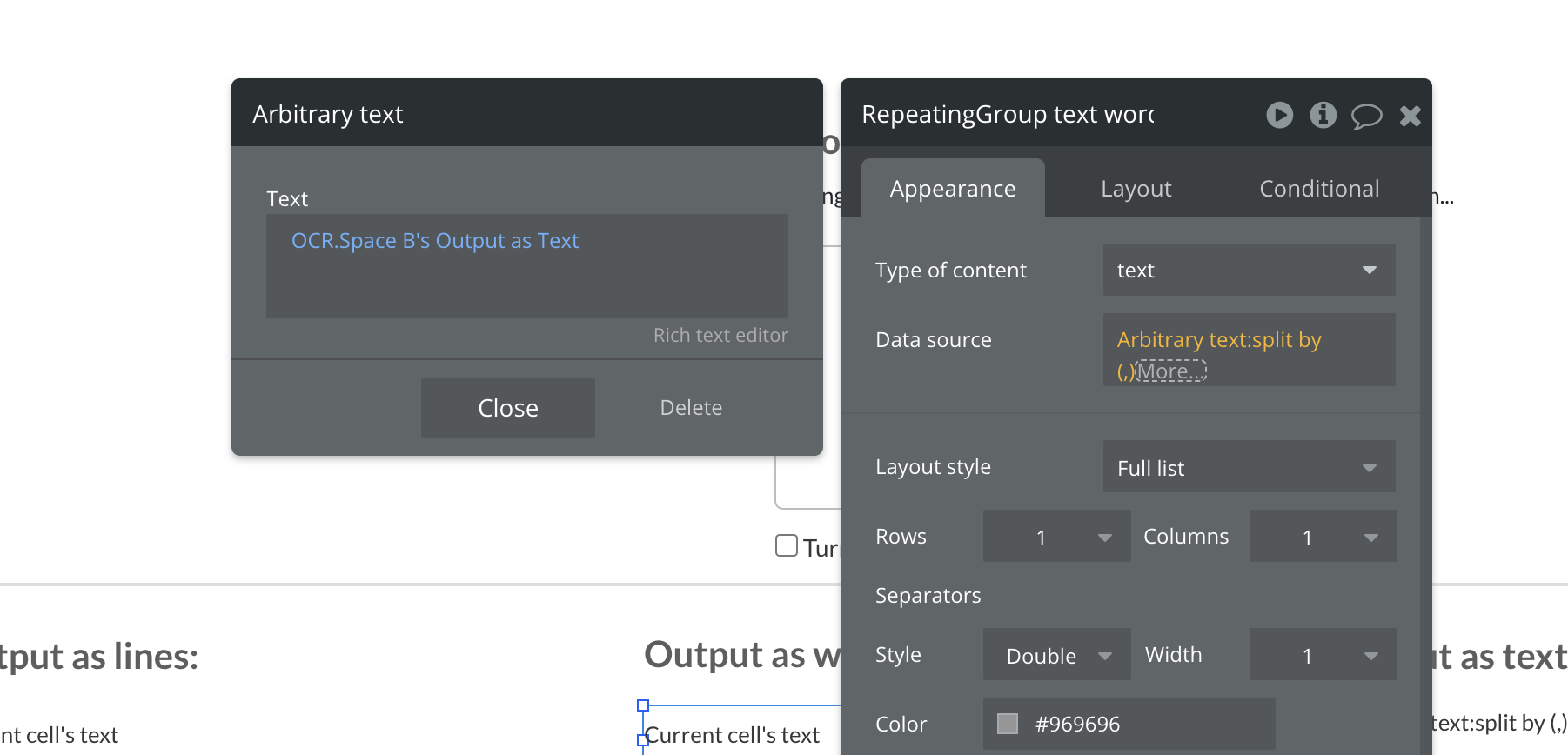
The simplest way to fix this would be a method where I can make the OCR text extract as a single line of text or even just as plain text without going to a new line unless the available space forces the text on to a new line. I’ve tried all available extraction formats and each will go to a new line if there’s a new line in the scanned text. Is it possible to add a single line option, or am I maybe missing something/doing it wrong?